Modelling a river in a cross-section#
This notebook shows how to model a river with tidal fluctuations, based on an example from an old program called WATEX, which was used to derive the head beneath levee structures for input into geotechnical stability calculations.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import timflow
import timflow.transient as tft
timflow.show_versions()
timflow version : 0.1.0
Python version : 3.13.3
Numpy version : 2.3.5
Numba version : 0.63.1
Scipy version : 1.17.0
Pandas version : 3.0.0
Matplotlib version : 3.10.8
LmFit version : 1.3.4
System description#
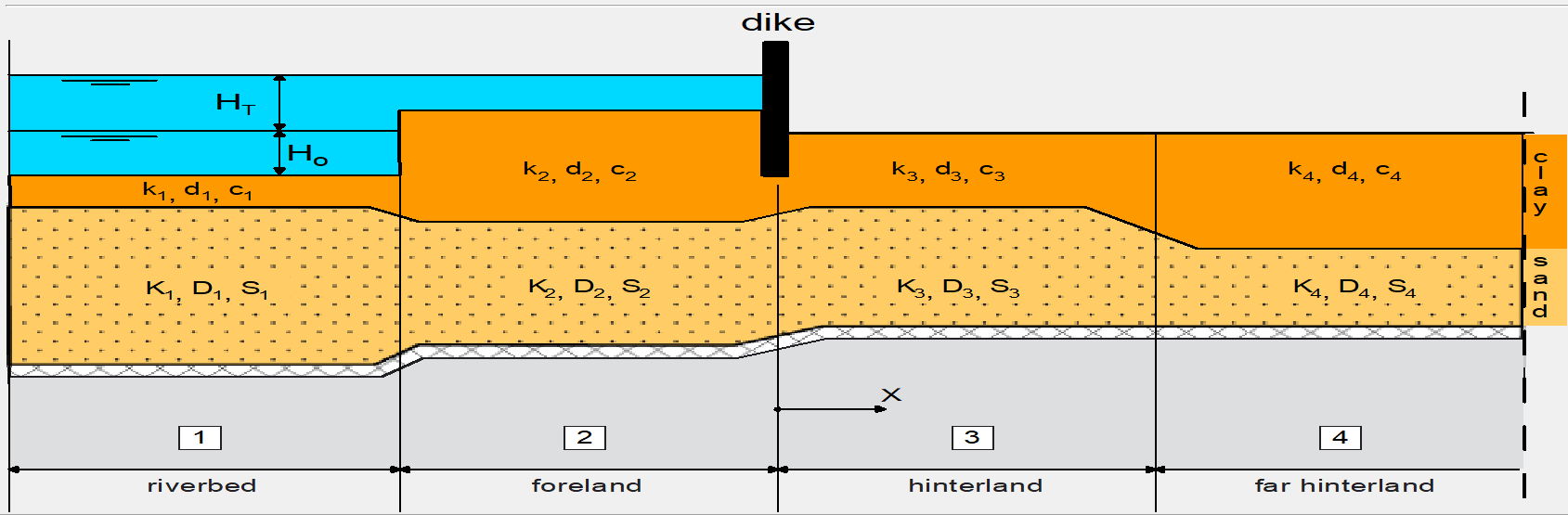
The system we want to model is shown below. It consists of 4 sections:
River: the summer bed of the river cuts deeper into the subsurface than the other sections
Foreland: the winter bed of the river due to higher water levels
Hinterland: the polder area protected by a dike or levee
Far hinterland: same as hinterland, but optionally with different parameters.
Aquifer properties and parameters#
We will define some aquifer properties and parameters for each of the sections based on subsurface data. Note that we’re modeling the hinterland and far-hinterland as one section in this example.
In a subsequent step the geohydrological parameters will be calibrated.
# cross-sections
L_river = 75.00 # m, width river, though it extends to -infinity
L_foreland = 28.00 # m, width foreland
L_hinterland = 4000.00 # m, width hinterland, extends to +infinity
x0 = -(L_river + L_foreland) # set x=0 at river bank
# layer elevations
ztop_riverbed = 1.00 # surface level in riverbed
ztop_foreland = 8.0 # surface level in foreland
ztop_hinterland = 8.0 # surface level in hinterland
ztop_aquifer = 0.0 # top of aquifer
zbot = -30.0 # bottom of aquifer
# geohydrology
kh = 10.0 # m/d, hydraulic conductivity
Saq = 1e-4 # 1/m, specific storage
Sll_river = 1e-6 # 1/m, specific storage aquitard
Sll_hinterland = 1e-3 # 1/m, specific storage aquitard
c_river = 100.0 # d, resistance riverbed
c_foreland = 150.0 # d, resistance foreland
c_hinterland = 500.0 # d, resistance hinterland
# set z-arrays for model
z_river = [ztop_riverbed, ztop_aquifer, zbot]
z_foreland = [ztop_foreland, ztop_aquifer, zbot]
z_hinterland = [ztop_hinterland, ztop_aquifer, zbot]
Load river levels#
Load data from csv file containing observed water levels relative to the mean observed water level for an 8-day period. The file contains the river stage and measurements from 2 piezometers next to the river. The water level at the polder is set to a constant value of 0.0 (i.e. no changes caused by river stage fluctuations).
data = pd.read_csv("data/watex_example.csv", index_col=[0])
data.head()
| rivier | kruin | binnenteen | polder | |
|---|---|---|---|---|
| T [days] | ||||
| 0.000000 | 0.000 | 0.000 | 0.000 | 0 |
| 0.020833 | 0.150 | 0.173 | 0.091 | 0 |
| 0.041667 | 0.160 | 0.177 | 0.091 | 0 |
| 0.062500 | 0.187 | 0.182 | 0.089 | 0 |
| 0.083333 | 0.197 | 0.185 | 0.085 | 0 |
data.plot(figsize=(10, 2), grid=True)
<Axes: xlabel='T [days]'>
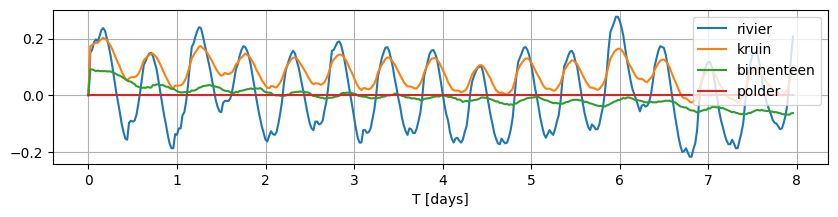
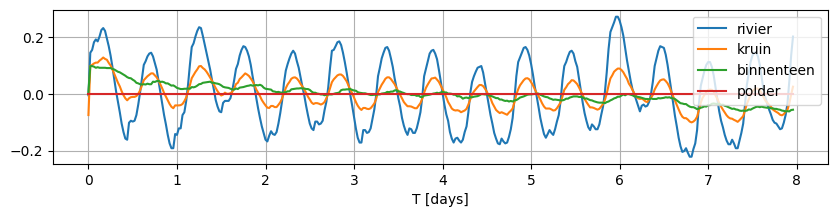
Note that the observed fluctuations do not fluctuate around 0 for each of these locations. In order to model this system with timflow, we need the variation to be around 0.0, therefore, we normalize each time series by subtracting the mean.
data_norm = data - data.mean()
data_norm.plot(figsize=(10, 2), grid=True);
Build the cross-section model#
Now we can build the cross-section model.
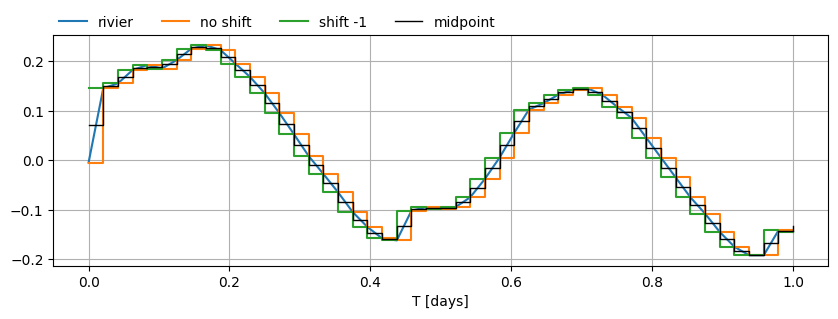
First, we need to define the river levels for the top boundary condition in the river and foreland sections. We want a list of time waterlevel pairs for the river water level.
We’re dealing with a river under the influence of tides, which means we have to be careful when specifying the river level. timflow maintains a given water level from a specific time until the next specified water level.
The following plot shows how timflow inteprets the water level for different pre-processing steps on the input data. If we just pass in the river time series as is, we’re continually leading the observed water level (orange line). We want to make sure the timflow input meets the observed level about at the midpoint (black line) of each time interval.
data_norm.loc[:1, "rivier"].plot(figsize=(10, 3), grid=True)
plt.step(
data_norm.loc[:1].index,
data_norm.loc[:1, "rivier"],
where="post",
label="no shift",
)
plt.step(
data_norm.loc[:1].index,
data_norm.loc[:1, "rivier"].shift(-1),
where="post",
label="shift -1",
)
mid = (data_norm.loc[:, "rivier"] + data_norm.loc[:, "rivier"].shift(-1).values).divide(2)
plt.step(
mid.loc[:1].index, mid.loc[:1], where="post", label="midpoint", color="k", lw=1.0
)
plt.legend(loc=(0, 1), frameon=False, ncol=4);
# tsandhstar = data_norm["rivier"].to_frame().to_records().tolist() # original
tsandhstar = mid.dropna().to_frame().to_records().tolist() # midpoint
# tsandhstar = (
# data_norm["rivier"].shift(-1).dropna().to_frame().to_records().tolist()
# ) # shift-1
ml = tft.ModelXsection(naq=1, tmin=1e-4, tmax=1e2)
river = tft.XsectionMaq(
ml,
-np.inf, # river extends to infinitiy
x0 + L_river,
z=z_river,
kaq=kh,
Saq=Saq,
Sll=Sll_river,
c=c_river,
topboundary="semi",
tsandhstar=tsandhstar,
name="river",
)
foreland = tft.XsectionMaq(
ml,
x0 + L_river,
x0 + L_river + L_foreland,
kaq=kh,
z=z_foreland,
Saq=Saq,
Sll=Sll_river,
c=c_foreland,
topboundary="semi",
tsandhstar=tsandhstar,
name="foreland",
)
hinterland = tft.XsectionMaq(
ml,
x0 + L_river + L_foreland,
np.inf, # hinterland extends to infinity
kaq=kh,
z=z_hinterland,
Saq=Saq,
Sll=Sll_hinterland,
c=c_hinterland,
topboundary="semi",
name="hinterland",
)
ml.solve()
self.neq 4
solution complete
Check the sections
river, foreland, hinterland
(river: XsectionMaq [-inf, -28.0] with h*(t),
foreland: XsectionMaq [-28.0, 0.0] with h*(t),
hinterland: XsectionMaq [0.0, inf])
Note that all sections are also stored in a dictionary where the names are used that were specified with the name keyword (in this case they were the same as the variable in which each section was stored).
ml.aq.inhomdict
{'river': river: XsectionMaq [-inf, -28.0] with h*(t),
'foreland': foreland: XsectionMaq [-28.0, 0.0] with h*(t),
'hinterland': hinterland: XsectionMaq [0.0, inf]}
Plot a cross-section of the model. Note the water level is just schematic in this picture.
ml.plots.xsection(
xy=[(x0 - 25, 0), (100, 0)], labels=False, params=True, names=True, hstar=10, sep="\n"
)
<Axes: xlabel='x', ylabel='elevation'>
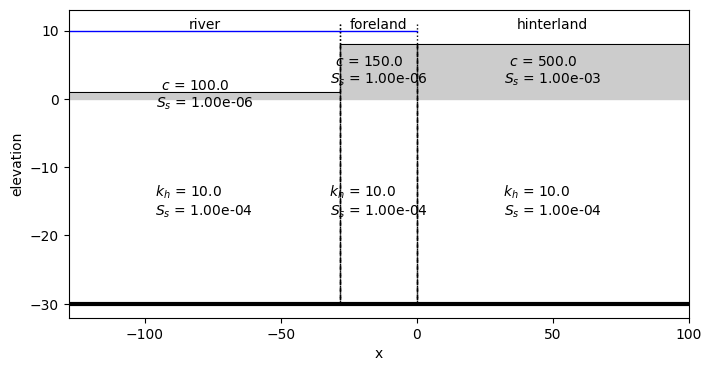
Show the summary of aquifer parameters for each section:
ml.aquifer_summary()
| layer | layer_type | k_h | c | S_s | ||
|---|---|---|---|---|---|---|
| # | ||||||
| river | 0 | 0 | leaky layer | NaN | 100.0 | 0.000001 |
| 1 | 0 | aquifer | 10.0 | NaN | 0.0001 | |
| foreland | 0 | 0 | leaky layer | NaN | 150.0 | 0.000001 |
| 1 | 0 | aquifer | 10.0 | NaN | 0.0001 | |
| hinterland | 0 | 0 | leaky layer | NaN | 500.0 | 0.001 |
| 1 | 0 | aquifer | 10.0 | NaN | 0.0001 |
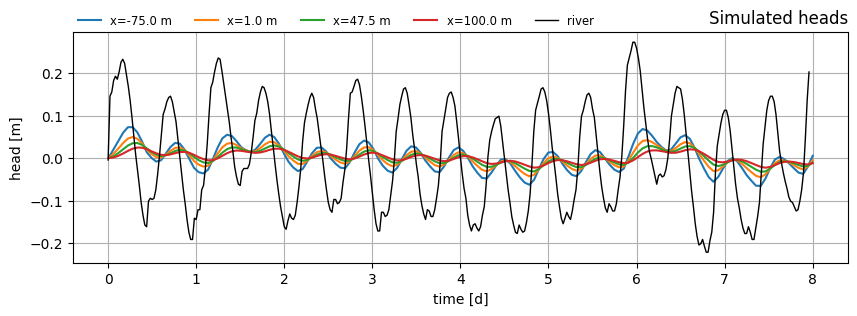
Plot head over time at several x-locations.
t = np.linspace(0.01, 8, 150)
xlocs = [
-75.0, # in river section
1.0, # at observation well 1
47.5, # at observation well 2
100.0, # in hinterland section
]
f, ax = plt.subplots(1, 1, figsize=(10, 3))
for i in range(len(xlocs)):
h = ml.head(xlocs[i], 0.0, t)
ax.plot(t, h[0], label=f"x={xlocs[i]:.1f} m")
ax.plot(data_norm.index, data_norm["rivier"], color="k", label="river", lw=1.0)
ax.legend(loc=(0, 1), frameon=False, ncol=5, fontsize="small")
ax.set_xlabel("time [d]")
ax.set_ylabel("head [m]")
ax.set_title("Simulated heads", loc="right")
ax.grid()
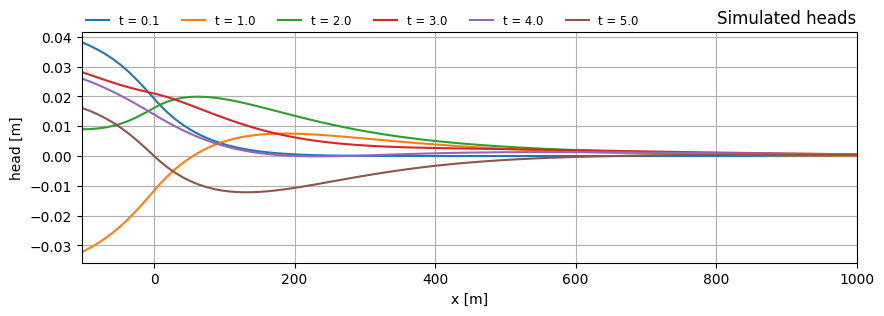
Plot head along x for multiple times
t = np.array([0.1, 1.0, 2.0, 3.0, 4.0, 5.0])
x = np.linspace(x0, 1000.0, 101)
y = np.zeros_like(x)
h = ml.headalongline(x, y, t)
f, ax = plt.subplots(1, 1, figsize=(10, 3))
for i in range(len(t)):
ax.plot(x, h[0, i], label="t = {:.1f}".format(t[i]))
ax.legend(loc=(0, 1), frameon=False, ncol=8, fontsize="small")
ax.set_xlabel("x [m]")
ax.set_ylabel("head [m]")
ax.grid()
ax.set_title("Simulated heads", loc="right")
ax.set_xlim(x0, x.max());
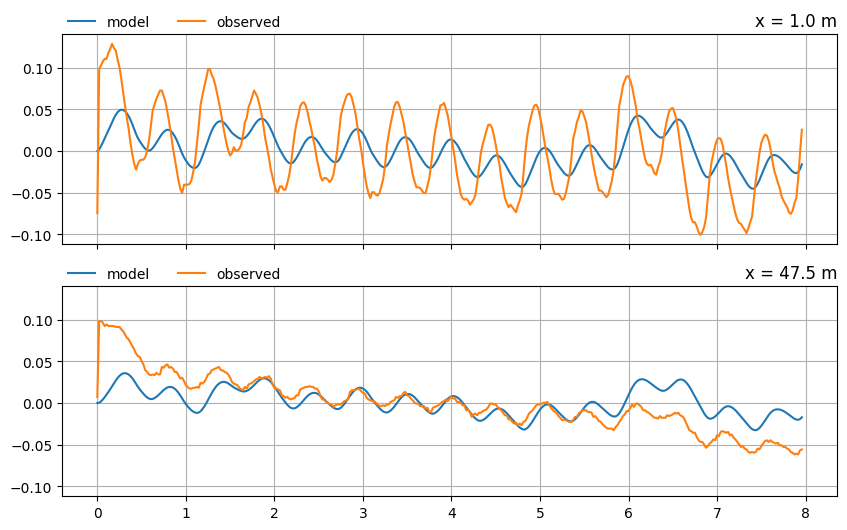
Compare the model results to the observed heads in the two piezometers at \(x = 1.0\) m and \(x = 47.5\) m.
# piezometer locations in cross-section
xpb_kr = 1.0
xpb_bite = 47.5
xlocs = [xpb_kr, xpb_bite]
t = data_norm.index.to_numpy()
f, axes = plt.subplots(len(xlocs), 1, figsize=(10, 6), sharex=True, sharey=True)
for i in range(len(xlocs)):
h = ml.head(xlocs[i], 0.0, t)
axes[i].plot(t, h[0], label="model")
hobs = data_norm.iloc[:, i + 1]
axes[i].plot(hobs.index, hobs, label="observed")
axes[i].set_title(f"x = {xlocs[i]} m", loc="right")
axes[i].legend(loc=(0, 1), frameon=False, ncol=2)
axes[i].grid()
Calibrate model on observed heads#
The model simulation is reasonable at the second observation well , but it clearly isn’t as good at the river bank. Let’s see if we can improve the fit of the model to the observations by calibrating the aquifer parameters.
Since the data at \(t=0\) shows some jumps, we want to give the model some spin-up time before we start fitting to the data. We set a tstart value to select only observations after this moment.
The following parameters will be calibrated:
\(k_h\) and \(S_s\) of the aquifer, this parameter should be the same in each section.
resistance \(c\) of the confining units, this parameter can vary within each section.
specific storage (\(S_s\)) for the leaky layers of the river and foreland, and separately the specific storage of the leaky layer in the hinterland.
In total this means we have 7 parameters that can vary in this calibration step.
tstart = 2.0 # model spin-up time, calibrate on timeseries after 2 days
# create calibrate object
cal = tft.Calibrate(ml)
# set observation time series
cal.series(
"kruin",
xpb_kr,
0.0,
layer=0,
t=data_norm.loc[tstart:, "kruin"].index.to_numpy(),
h=data_norm.loc[tstart:, "kruin"].values,
)
cal.series(
"binnenteen",
xpb_bite,
0.0,
layer=0,
t=data_norm.loc[tstart:, "binnenteen"].index.to_numpy(),
h=data_norm.loc[tstart:, "binnenteen"].values,
)
# define parameters for calibration
cal.set_parameter(
"kaq",
layers=0,
initial=river.kaq[0],
pmin=1.0,
pmax=30.0,
inhoms=("river", "foreland", "hinterland"),
)
cal.set_parameter(
"Saq",
layers=0,
initial=river.Saq[0],
pmin=1e-6,
pmax=1e-2,
inhoms=("river", "foreland", "hinterland"),
)
cal.set_parameter(
"c",
layers=0,
initial=river.c[0],
pmin=0.0,
pmax=100.0,
inhoms="river",
)
cal.set_parameter(
"c",
layers=0,
initial=foreland.c[0],
pmin=10.0,
pmax=500.0,
inhoms="foreland",
)
cal.set_parameter(
"c",
layers=0,
initial=hinterland.c[0],
pmin=10.0,
pmax=1000.0,
inhoms="hinterland",
)
cal.set_parameter(
"Sll",
layers=0,
initial=river.Sll[0],
pmin=1e-8,
pmax=1e-4,
inhoms=("river", "foreland"),
)
cal.set_parameter(
"Sll",
layers=0,
initial=hinterland.Sll[0],
pmin=1e-8,
pmax=1e-1,
inhoms="hinterland",
)
# run the calibration
cal.fit(report=False)
# cal.fit_least_squares(report=False, method="trf")
# print the RMSE
print(f"RMSE: {cal.rmse():.5f}")
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
..
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[17], line 83
73 cal.set_parameter(
74 "Sll",
75 layers=0,
(...) 79 inhoms="hinterland",
80 )
82 # run the calibration
---> 83 cal.fit(report=False)
84 # cal.fit_least_squares(report=False, method="trf")
85
86 # print the RMSE
87 print(f"RMSE: {cal.rmse():.5f}")
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/fit.py:391, in Calibrate.fit(self, report, printdot, **kwargs)
388 def fit(self, report=False, printdot=True, **kwargs):
389 # current default fitting routine is lmfit
390 # return self.fit_least_squares(report) # does not support bounds by default
--> 391 return self.fit_lmfit(report, printdot, **kwargs)
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/fit.py:332, in Calibrate.fit_lmfit(self, report, printdot, **kwargs)
330 self.lmfitparams.add(name, value=p["initial"], min=p["pmin"], max=p["pmax"])
331 fit_kws = {"epsfcn": 1e-4} # this is essential to specify step for the Jacobian
--> 332 self.fitresult = lmfit.minimize(
333 self.residuals_lmfit,
334 self.lmfitparams,
335 method="leastsq",
336 kws={"printdot": printdot},
337 **fit_kws,
338 **kwargs,
339 )
340 print("", flush=True)
341 print(self.fitresult.message)
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/lmfit/minimizer.py:2616, in minimize(fcn, params, method, args, kws, iter_cb, scale_covar, nan_policy, reduce_fcn, calc_covar, max_nfev, **fit_kws)
2476 """Perform the minimization of the objective function.
2477
2478 The minimize function takes an objective function to be minimized,
(...) 2610
2611 """
2612 fitter = Minimizer(fcn, params, fcn_args=args, fcn_kws=kws,
2613 iter_cb=iter_cb, scale_covar=scale_covar,
2614 nan_policy=nan_policy, reduce_fcn=reduce_fcn,
2615 calc_covar=calc_covar, max_nfev=max_nfev, **fit_kws)
-> 2616 return fitter.minimize(method=method)
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/lmfit/minimizer.py:2355, in Minimizer.minimize(self, method, params, **kws)
2352 if (key.lower().startswith(user_method) or
2353 val.lower().startswith(user_method)):
2354 kwargs['method'] = val
-> 2355 return function(**kwargs)
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/lmfit/minimizer.py:1674, in Minimizer.leastsq(self, params, max_nfev, **kws)
1672 result.call_kws = lskws
1673 try:
-> 1674 lsout = scipy_leastsq(self.__residual, variables, **lskws)
1675 except AbortFitException:
1676 pass
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/scipy/optimize/_minpack_py.py:439, in leastsq(func, x0, args, Dfun, full_output, col_deriv, ftol, xtol, gtol, maxfev, epsfcn, factor, diag)
437 if maxfev == 0:
438 maxfev = 200*(n + 1)
--> 439 retval = _minpack._lmdif(func, x0, args, full_output, ftol, xtol,
440 gtol, maxfev, epsfcn, factor, diag)
441 else:
442 if col_deriv:
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/lmfit/minimizer.py:540, in Minimizer.__residual(self, fvars, apply_bounds_transformation)
537 self.result.success = False
538 raise AbortFitException(f"fit aborted: too many function evaluations {self.max_nfev}")
--> 540 out = self.userfcn(params, *self.userargs, **self.userkws)
542 if callable(self.iter_cb):
543 abort = self.iter_cb(params, self.result.nfev, out,
544 *self.userargs, **self.userkws)
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/fit.py:291, in Calibrate.residuals_lmfit(self, lmfitparams, printdot)
289 vals = lmfitparams.valuesdict()
290 p = np.array([vals[k] for k in self.parameters.index])
--> 291 return self.residuals(p, printdot)
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/fit.py:271, in Calibrate.residuals(self, p, printdot, weighted, layers, series)
268 for parray in parraylist:
269 # [:] needed to do set value in array
270 parray[:] = p[i]
--> 271 self.model.solve(silent=True)
273 rv = np.empty(0)
274 cal_series = self.seriesdict.keys() if series is None else series
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/model.py:623, in TimModel.solve(self, printmat, sendback, silent)
621 """Compute solution."""
622 # Initialize elements
--> 623 self.initialize()
624 # Compute number of equations
625 self.neq = np.sum([e.nunknowns for e in self.elementlist])
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/model.py:986, in ModelXsection.initialize(self)
984 def initialize(self):
985 self.check_inhoms()
--> 986 super().initialize()
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/model.py:116, in TimModel.initialize(self)
114 self.vbclist = [e for e in self.vbclist if not e.inhomelement]
115 self.zbclist = [e for e in self.zbclist if not e.inhomelement]
--> 116 self.aq.initialize()
117 self.gvbclist = self.gbclist + self.vbclist
118 self.vzbclist = self.vbclist + self.zbclist
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/aquifer.py:338, in SimpleAquifer.initialize(self)
336 def initialize(self):
337 for inhom in self.inhomdict.values():
--> 338 inhom.initialize()
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/inhom1d.py:155, in Xsection.initialize(self)
154 def initialize(self):
--> 155 super().initialize()
156 self.create_elements()
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/aquifer.py:131, in AquiferData.initialize(self)
129 b = np.diag(np.ones(self.naq))
130 for i in range(self.model.npval):
--> 131 w, v = self.compute_lab_eigvec(self.model.p[i])
132 # Eigenvectors are columns of v
133 self.eigval[:, i] = w
File ~/checkouts/readthedocs.org/user_builds/timflow/envs/27/lib/python3.13/site-packages/timflow/transient/aquifer.py:172, in AquiferData.compute_lab_eigvec(self, p, returnA, B)
170 dm1 = -b[1:] / (self.c[1:] * self.T[:-1])
171 dp1 = -b[1:] / (self.c[1:] * self.T[1:])
--> 172 A = np.diag(dm1, -1) + np.diag(d0, 0) + np.diag(dp1, 1)
173 if returnA:
174 return A
KeyboardInterrupt:
Show calibration parameters results
cal.parameters.iloc[:, :-2]
Plot the locations of observation wells.
ax = river.plot(labels=False, params=False, names=True)
foreland.plot(ax=ax, names=True)
hinterland.plot(ax=ax, params=False, names=True)
ml.elementlist[0].plot(ax=ax, hstar=10.0)
ml.elementlist[1].plot(ax=ax, hstar=10.0)
ax.set_xlim(x0, 100.0)
ax.set_ylim(-30, 20)
cal.xsection(ax=ax);
Plot the modeled vs. observed time series for both observation wells after calibration.
# piezometer locations in cross-section
xpb_kr = 1.0
xpb_bite = 47.5
xlocs = [xpb_kr, xpb_bite]
t = data_norm.index.to_numpy()
f, axes = plt.subplots(len(xlocs), 1, figsize=(10, 6), sharex=True, sharey=True)
for i in range(len(xlocs)):
h = ml.head(xlocs[i], 0.0, t)
axes[i].plot(t, h[0], label="model")
hobs = data_norm.loc[tstart:].iloc[:, i + 1] # showing calibration selection
axes[i].plot(hobs.index, hobs, label="observed")
axes[i].set_title(f"x = {xlocs[i]} m", loc="right")
axes[i].legend(loc=(0, 1), frameon=False, ncol=2)
axes[i].grid()
Let’s take a look at the calibrated aquifer parameters.
(
ml.aquifer_summary()
.style.format(na_rep="-", precision=2)
.format("{:.2e}", subset=["S_s"])
)
Discussion#
The calibration result shows that the specific storage of the leaky layer in the hinterland section is orders of magnitude higher than the other specific storage terms. Also the resistance of the confining unit is higher in the foreland than it is in the polder.
These results have to be analyzed further to determine whether these results make physical sense. The fit to the observed data is reasonable, but the problem is likely over-parametrized. It is not possible to estimate all parameters separately, since there are infinite combinations of parameters that fit the data equally well. This causes the problem to be highly sensitive to the starting values of parameters, as well as the selected optimization method.
Some other points that could influence the results:
Only two piezometers in the cross-section.
The downwards trend in the head observations in the second piezometer probably isn’t ideal as
timflowwill never be able to simulate that trend with the current input data.The time series are supposedly presented relative to a mean observed head/water level, but somehow do not fluctuate around 0.0, which mean they had to be normalized (again) for the
timflowsimulation.Neglecting the storage of the leaky layers yields a physically improbable solution where all resistance is put underneath the river section, and the foreland and hinterland have a resistance on the minimum parameter boundary. However, it is usually not expected that the storage in the leaky layers has such a large influence on the outcome. In many models this parameter is neglected altogether.